Three Types of Machine Learning
Machine learning is the heart of AI. Similar to any species, AI needs continuous learning. So, let’s see how we make AI learn and what types of machine learning are there.
In this article, we will understand the three different types of Machine Learning; however, we must first understand Artificial Intelligence.
Artificial Intelligence (AI) is the ability of a computer or a computer-controlled robot to perform tasks that humans usually.
AI is made up of two types of approaches:
- Symbolic, or “top-down,” – seeks to replicate intelligence by analyzing cognition. It is purely independent of the brain’s structure and processes through symbols.
- Connectionist, or “bottom-up,” – involves creating artificial neural networks that imitate/replicate the brain’s structure.
What is Machine Learning and Its Types
Machine learning is a part of artificial intelligence that allows models to continuously learn by using past experiences, exploring data, and identifying patterns with little human intervention.
Machine learning (ML) teaches computers to learn from data to make accurate predictions or decisions.
A striking feature of ML is its versatility and applicability to many problems, from predicting disease outbreaks to recommending your next favorite movie. Though this domain is remarkably vast, it primarily unfolds into three fundamental categories:
There are three different types of Machine Learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Each type reflects a different approach to learning from data and serves a distinct purpose, tailored to specific problems and scenarios in various fields. We’ll explore each type’s typical characteristics, applications, and examples as we dive deeper.
We will discuss how the machine learning algorithm learns from data and how these methods facilitate intelligent decision-making across diverse domains.
Supervised Learning
Considering that some of our readers may also be new to the concept of machine learning, let’s discuss supervised machine learning in layman’s terms.
Supervised Machine Learning for the Beginners
Imagine teaching a child to recognize and name fruits – an apple, for example. You show them several pictures of apples, and each time, you say, “This is an apple.” The child sees various apples – green ones, red ones, big ones, and small ones. They hear the word “apple” associated with the picture each time. Eventually, the child starts to identify what characteristics make an apple – perhaps the round shape, the stem at the top, or a particular range of colors.
Now, when you show the child a new picture of an apple, even one they’ve never seen before, they identify it correctly. Why? Because through repeated examples (the training), they’ve learned to associate specific features (shape, color, stem) with the label “apple.”
In machine learning, this process is akin to supervised learning.
- The child is the algorithm.
- The pictures of apples are the data.
- Your repeated saying, “This is an apple,” is the labeling.
- The model training is the child’s learning process, identifying features like shape and color.
- The child’s ability to name a new fruit correctly is the prediction.
In a real-world machine learning application, let’s say email spam detection:
- The algorithm (the “child”) is fed many emails (the “apples”).
- Each email is labeled as “spam” or “not spam” (the “This is an apple” part).
- The algorithm learns which features (such as certain words or patterns) are common in spam emails during the training process (learning what an “apple” looks like).
- Once trained, the algorithm can predict whether a new, unseen email is spam or not spam (identifying the new “apple”).
So, supervised learning is about learning a function from labeled training data that allows us to predict unseen or future data—just like a child learning from labeled pictures of fruit!
Technical Aspects of Supervised Machine Learning
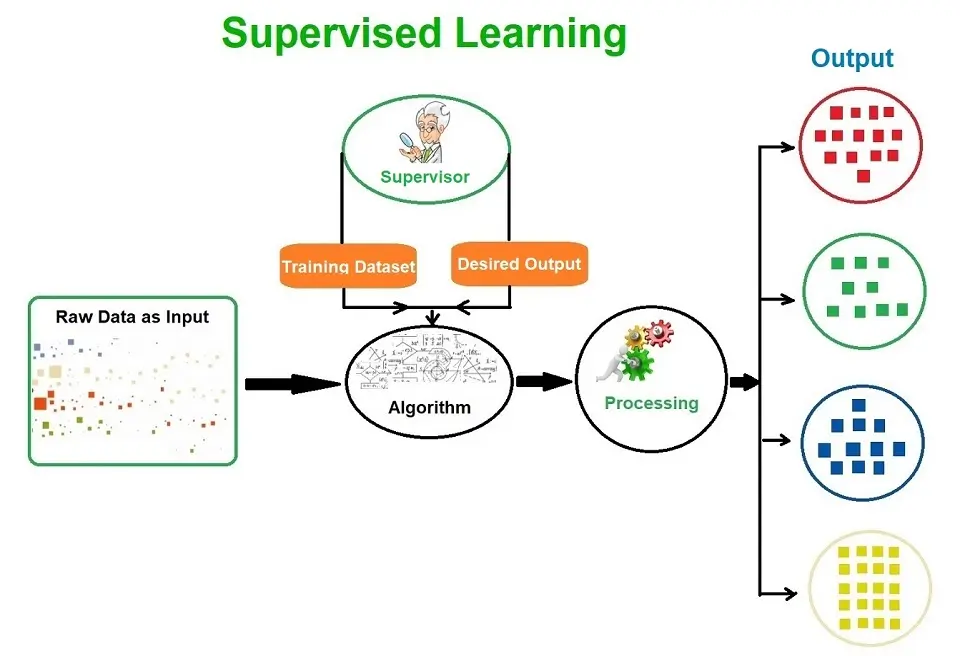
Supervised Learning is when the algorithm learns on a labeled dataset and analyses the training data. These labeled data sets have inputs and expected outputs. The meaning of the labeled data is the date that is tagged with labels to identify the characteristics, properties, or classifications.
Supervised Learning’s algorithm is trained on input data labeled for a specific output. A supervised training model aims to detect the relationships and patterns of the input data and output with the help of the labels. This enables the model to achieve accurate labeling results with inputs it had not seen in the past.
The dataset is labeled. Therefore, we know the correct answers. One way to remember Supervised Learning is by comparing it to the teacher supervising the learning process.
The teacher (supervisor) knows the answers, whereas the student (the algorithm) is still going through the learning process (the labeled data). If the student (algorithm) gets something wrong, the teacher will guide the student to correct the outputs produced. The learning process does not stop until the student (algorithm) achieves a specific level of accurate performance.
The image below shows input data with different variables and data points. The supervisor (teacher) has the training data set and knows the desired outputs. The algorithms, i.e., the student learns and processes the input data and produces the correct outputs with the help of the supervisor, i.e., the teacher.
Types of Supervised Machine Learning
within supervised learning, there are typically two main categories based on the type of output or prediction the model is making:
- Classification: In classification tasks, the output variable is a category, such as “spam” or “not spam” in email filtering. The model is trained to categorize the input data into discrete labels. Classification can be binary, with only two categories, or multi-class, with more than two categories of outputs. Examples include image recognition (where inputs are images and outputs are labels), disease diagnosis, and sentiment analysis.
- Regression: In regression tasks, the output variable is a continuous value or a real number, such as “house price” or “temperature.” The model predicts the quantity given the input data. This could involve predicting prices, forecasting weather, estimating values, etc. Regression analysis is about predicting numerical value based on historical data.
Within these categories, there are various algorithms and techniques that can be applied depending on the nature of the problem and the data available. Here are a few examples:
- For classification:
- Logistic Regression
- Decision Trees
- Support Vector Machines (SVM)
- K-Nearest Neighbors (KNN)
- Random Forests
- Neural Networks
- Naive Bayes
- For regression:
- Linear Regression
- Polynomial Regression
- Support Vector Regression (SVR)
- Decision Trees and Random Forest Regression
- Lasso Regression
- Ridge Regression
- Elastic Net
- Neural Networks
Note about the Various Types Of Supervised Learning
Each of these algorithms has its own strengths and weaknesses, and the choice of which to use can depend on the size and nature of your data, the accuracy required, the prediction speed needed, the complexity of the problem, and the interpretability of the model.
Unsupervised Learning
Similar to supervised learning, let us first discuss unsupervised machine learning as beginners.
Unsupervised Machine Learning for Beginners
Imagine walking into a room full of various toys for the first time – balls, teddy bears, dolls, and cars. Nobody tells you what each item is or how they’re grouped.
However, after exploring the toys, you might naturally start organizing them. Perhaps you group them based on similarities and differences that you observe—all the balls together because they are round, all the teddy bears together because they are soft and fluffy, etc.
You don’t know the names or purposes of these toys (since no one told you), but you’re finding structure in the collection based on inherent characteristics.
In unsupervised learning:
- You are the algorithm.
- The toys are the data.
- Grouping similar toys represents clustering, one of the key techniques in unsupervised learning.
In a practical machine-learning scenario, imagine having a dataset of various flowers without any labels indicating their types. Unsupervised learning algorithms explore the dataset and might group (or cluster) the flowers together based on similar features, such as petal size, shape, or color, without knowing the names of the flower types.
In essence, unsupervised learning seeks to identify inherent patterns or structures in data without using predefined labels. The algorithm explores the data, finds relationships within it, and typically groups it into clusters or identifies the underlying distribution of the data.
It’s like providing the algorithm with a puzzle and letting it figure out how to group the pieces without showing it the full picture on the puzzle box!
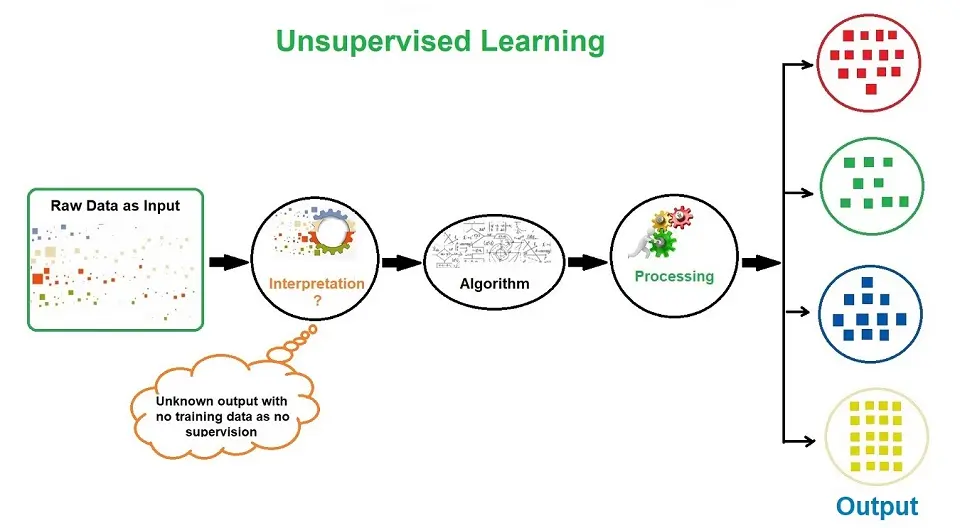
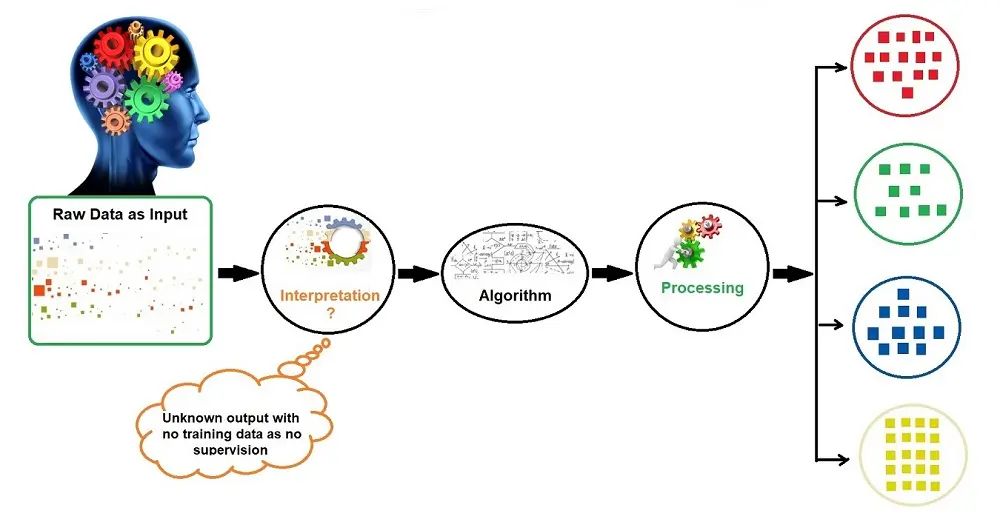
Technical Aspects of Unsupervised Machine Learning
Wikipedia’s definition of Unsupervised Learning is:
“Unsupervised Learning is an algorithm that learns patterns from untagged data. The hope is that through mimicry, which is an important mode of learning in people, the machine is forced to build a compact internal representation of its world and then generate imaginative content from it.”
This is a complex definition. To break it down into Layman’s terms, Unsupervised Learning learns on unlabeled data, inferring more about hidden structures to produce accurate and reliable outputs.
To help you understand Unsupervised Learning better, I will use the same concept of the teacher and the student. The data has no specific structure, meaning it has no training data, and the outputs are unknown as there is no supervision (teacher).
Therefore, the student (the algorithm) has to identify the structure without any help from the teacher by making its own interpretations. The algorithms (student) learn and process the data through interpretation and produce outputs.
The image below shows the raw input data. However, no supervision (teacher) guides the algorithm (student) with training data or known outputs. Therefore, it makes its interpretations, and the algorithm (student) learns and processes outputs.
Types of Unsupervised Machine Learning
within unsupervised learning, there are several categories based on the task’s nature. Here are the primary ones:
- Clustering: This is the task of grouping a set of objects so that objects in the same group (a cluster) are more similar to each other than those in other groups. Common clustering algorithms include:
- K-Means
- Hierarchical Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaussian Mixture Models
- Mean Shift
- Association: Association rules are used to discover relationships between variables in large databases. It’s a rule-based machine learning method for discovering interesting relationships between large databases’ variables. An example algorithm is:
- Apriori
- Eclat
- FP-Growth
- Dimensionality Reduction: This reduces the number of random variables under consideration, which can be divided into feature selection and feature extraction. Techniques include:
- Principal Component Analysis (PCA)
- Singular Value Decomposition (SVD)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Autoencoders
- Anomaly Detection: The identification of rare items, events, or observations that raise suspicions by differing significantly from most of the data. Techniques include:
- Isolation Forest
- One-Class SVM
- Local Outlier Factor (LOF)
- Autoencoders (when used for reconstruction error)
- Neural Network-Based Approaches: With advancements in deep learning, there are unsupervised neural network architectures designed for unsupervised tasks:
- Generative Adversarial Networks (GANs)
- Self-Organizing Maps (SOM)
- Deep Belief Networks (DBNs)
- Variational Autoencoders (VAEs)
Note about the Various Types Of Unsupervised Learning
Each category serves different purposes and is useful in various scenarios. For example, clustering is widely used for market segmentation. At the same time, dimensionality reduction is often a preprocessing step to improve the performance of supervised learning algorithms by reducing overfitting and computation time.
Reinforcement Learning
Well, here is an introduction to “Reinforcement Learning” in an easy-to-understand way if you are a beginner to the concept of machine learning:
Reinforcement Machine Learning for Beginners
Imagine training a dog to fetch a ball. The first time you throw the ball, the dog might not know what to do and may not retrieve it.
However, if it brings the ball back, you treat the dog. Quickly, the dog realizes: “Ah, when I fetch the ball, I get a reward!” From then on, it’s likely to fetch the ball to earn more treats. It might refine its approach – fetching it faster or returning it more accurately to your hand – to secure its reward more efficiently.
Various Elements in the above Scenario for Reinforcement Learning
Here’s how this scenario relates to reinforcement learning:
- The dog represents the learning algorithm or agent.
- The environment is where you and the dog are playing.
- The action is fetching the ball.
- The reward is the treat – positive if the ball is fetched, perhaps nonexistent, or even negative if not.
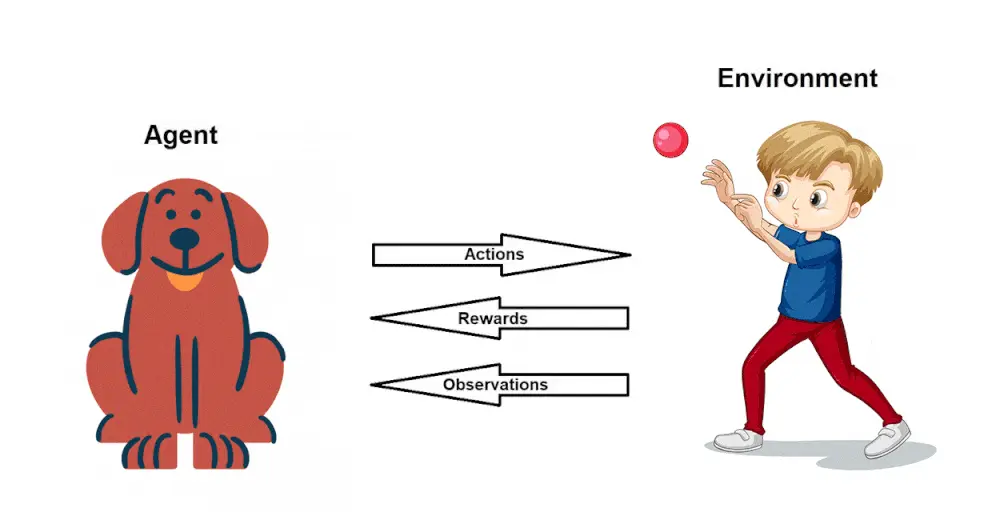
In reinforcement learning (RL), the agent (like the dog) interacts with its environment (like the playing field) by taking actions (like fetching) to achieve some notion of cumulative reward (like treats).
The agent isn’t told which actions to take but is given a reward or penalty based on its chosen actions. Over time, through trial and error, the agent learns the best actions to take in various states to maximize its cumulative reward.
In a computer science context, consider a chess-playing algorithm:
- The agent is the algorithm that plays chess.
- The environment is the chessboard.
- The action is moving a chess piece.
- The reward might be positive for taking an opponent’s piece and even larger for winning but negative for losing pieces or the game.
The algorithm (agent) learns by playing many games (interacting with the environment), gradually improving its strategy (policy) to make moves (actions) that increase its chance of winning (maximizing cumulative reward).
Through exploration, mistakes, and refinements, the reinforcement learning agents optimize their actions for long-term rewards. This is similar to how our canine friend learned to fetch the ball efficiently to earn treats!
Technical Aspects of Reinforcement Machine Learning
Reinforcement Learning is the third type of Machine Learning and is the training of machine learning models to make a sequence of decisions. It concerns how intelligent agents are to act in an environment to maximize cumulative reward.
Reinforcement Learning stems from Machine Learning. It aims to train a model to return an optimum solution. It uses a sequence of solutions and/or decisions created for a specific problem.
To understand reinforcement learning better, let’s first walk through the terminologies.
Reinforcement Learning terminology
Below is a list of terminologies that will be important for you to understand the overall concept of Reinforcement Learning.
- Actions: Actions are all the possible steps the model can take to yield a reward from the Environment. They are based on policy.
- Agent: This is the learning phase of Reinforcement Learning. The agent’s aim is to maximize the rewards the Environment gives it.
- Environment: In layman’s terms, this is the Agent’s home where it lives and interacts. The Agent performs actions within the Environment but cannot influence the dynamics of the Environment due to these actions.
- Episode: This is each of the repeated attempts by the Agent to help it learn the Environment. All the states come in between an initial state and a terminal state.
- Policy: This determines how an agent behaves and acts as a mapping method between the Agent’s present state and actions.
- Return: This is the sum of all the rewards the Agent expects to receive. The Agent does this following the policy from the state to the end of the episode.
- Reward: This numerical value comes from the Environment and is sent to the Agent. It is a response to the Agent’s actions in the Environment. There are three types of rewards: positive (desired action), negative (undesired action), and zero (no action).
- State: This is the current configuration of the Environment in which the Agent chooses to take action.
How does Reinforcement Learning work?
I will first review the Reinforcement Learning workflow and explore it with an example.
Reinforcement Learning Workflow:
Following are the steps in the overall workflow of reinforcement machine learning:
1. Define the Problem
Your first step would be defining the task the Agent will need to learn. This includes considering how the Agent will interact with the Environment and the goals it needs to achieve.
2. Setup the Environment
The next step is creating the Environment, ensuring the Agent can operate within it. There are two types of environments:
- Single-agent Environment: In this case, there is only one Agent that exists and interacts within the Environment
- Multi-agent environment: Here, we have more than one agent interacting within the Environment
The Environment can either be a simulation model or an actual physical system.
3. Define Reward Signals
In this step, you will define the reward signal that the Agent will use to perform tasks that meet the goals and the overall performance.
4. Create Agent
You are now ready to create your Agent, which consists of the agent policy representation and the reinforcement learning training algorithm. Here is a breakdown of what you will need to do for each part:
- Agent policy representation: You can use neural networks to choose a way to represent the policy.
- Training algorithm: You must select the appropriate training algorithm. For example, most modern reinforcement learning algorithms use neural networks.
5. Train and Validate the Agent
In this phase, you will train the agent policy representation using the Environment, agent learning algorithm, and the reward signal. In addition, you can use training options such as stopping criteria from tuning the policy.
You will then evaluate the training policy after training ends. In this stage, you will review the performance of the agent learning algorithm in the Environment and how effective it was using the reward signal.
You can tune the reward signal and policy architecture to improve the overall performance.
6. Deploy the Policy
This is the last phase of Reinforcement Learning. After that, you must deploy the training policy representation using, for example, generated C/C++ or CUDA code.
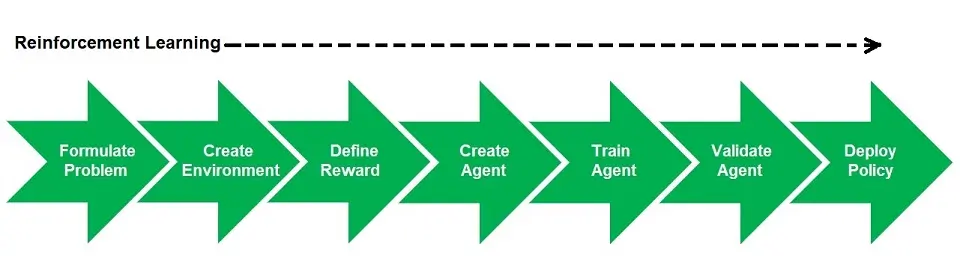
Let’s now use an example to implement this workflow. I will use the generic dog to perform a task and receive a reward. Let’s first define what is what.
The overall goal for this task is to train the dog to complete a specific task within an environment. For example, the Agent is the dog, and the Environment is the owner and the dog’s surroundings.
During the initial training stage, the dog (Agent) will not respond to commands correctly. For example, if the owner (Environment) asks the dog (Agent) to sit, it may run instead.
The dog (Agent) is learning and trying to understand its surroundings and associate specific observations, which leads it to act and receive a reward. This association stage for the dog (Agent), where it is trying to link observations and actions, is known as a policy.
The dog (Agent) wishes to learn and act on every observation correctly to receive as many rewards as possible. This represents the whole process of reinforcement learning, tuning the dog’s (Agent) policy to learn the correct behavior and receive rewards.
Once the training is complete, the dog (Agent) should be able to better and distinguish the observations the owner (Environment) is requesting and showing.
The image below shows the raw input data and the elements of the agent, which includes selecting algorithms, taking the best actions, understanding the complex environment, and hoping to receive an award. The arrows show the cyclical process of trial and error before producing accurate outputs.
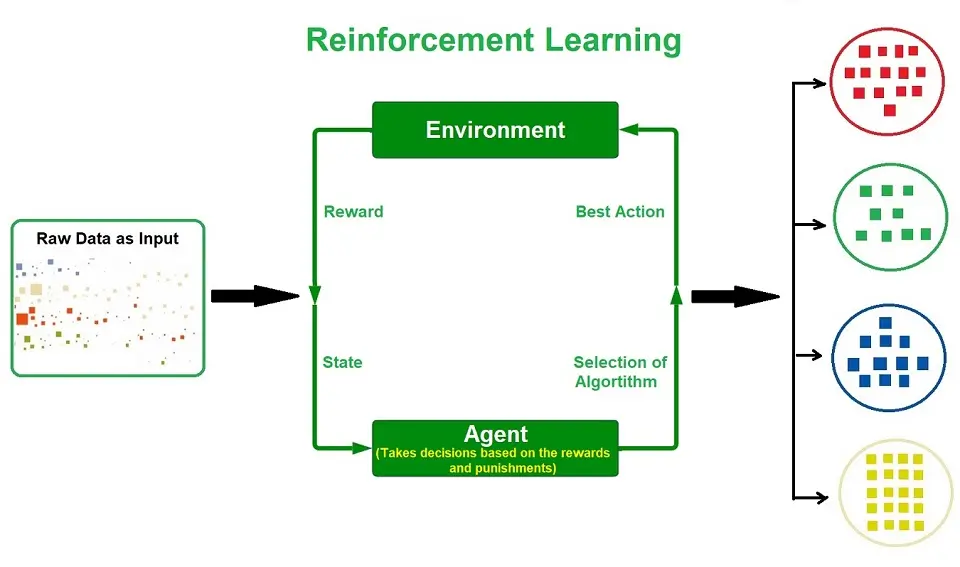
Types of Reinforcement Machine Learning
Within reinforcement learning, there are a few different categories based on the approach and the type of problem being addressed:
- Value-Based Methods: These methods focus on finding the value of each state or state-action pair and use these values to determine the optimal policy. The most common algorithms are:
- Q-learning
- SARSA (State-Action-Reward-State-Action)
- Deep Q-Networks (DQN), which combine Q-learning with deep neural networks
- Policy-Based Methods: In contrast to value-based methods, policy-based methods directly learn the policy function that maps state to action without requiring a value function. Examples include:
- REINFORCE
- Trust Region Policy Optimization (TRPO)
- Proximal Policy Optimization (PPO)
- Model-Based Methods: These approaches involve learning a model of the environment and using it to make decisions. This can lead to more efficient learning because it can use planning algorithms to decide the best actions. Examples include:
- Dyna-Q (combining Q-learning with a learned model of the environment)
- Model Predictive Control (MPC)
- Actor-Critic Methods: These methods combine value-based and policy-based methods. They have two components: an actor who suggests actions and a critic who evaluates them. Examples include:
- Advantage Actor-Critic (A2C)
- Asynchronous Advantage Actor-Critic (A3C)
- Soft Actor-Critic (SAC)
- Multi-Agent Reinforcement Learning: These are specialized methods for situations where multiple agents are learning at the same time. This can introduce complex dynamics because the optimal policy might depend on other agents’ policies.
- Independent Q-Learning
- Cooperative and Competitive Learning
- Hierarchical Reinforcement Learning: This breaks down the decision-making process into smaller subtasks, which can be easier to learn than a single complex policy.
- Options Framework
- Hierarchical Actor-Critic (HAC)
- Inverse Reinforcement Learning (IRL): Instead of learning to optimize the reward, IRL focuses on learning the reward function based on expert agents’ observed behavior.
- Apprenticeship Learning
- Maximum Entropy IRL
Note about the Various Types Of Reinforcement Learning
Each of these categories and methods has its applications, strengths, and limitations. For instance, value-based methods are typically simpler and more stable but might struggle with high-dimensional state spaces.
Policy-based methods can handle high-dimensional and continuous action spaces but might be less sample-efficient.
Actor-critic methods aim to combine the advantages of both, whereas model-based methods can be very efficient but rely on the quality of the model.
Differences of Various Kinds of Machine Learning
Supervised vs. Reinforcement Learning
To recap, in Supervised Learning, we have a supervisor who has knowledge of the environment, the training dataset, and the desired outputs. The supervisor shares this knowledge to help guide the algorithm to complete the task accurately. However, we have an agent who can independently perform several tasks in Reinforcement Learning. Therefore, there is no need for a supervisor.
Both of these Machine Learning types use a mapping between the output and input. They both aim to produce accurate outputs with the given raw input data. However, with Reinforcement Learning, a reward function helps the system learn from mistakes and improve itself independently, without any supervision, helping it improve its performance and understand its progress.
As the Machine Learning model learns from its own experiences, it gains knowledge and improves its future implementations through trial and error.
Reinforcement vs. Unsupervised Learning
We mentioned above that Supervised Learning and Reinforcement Learning have a mapping structure that guides the Machine Learning model from input to output. However, Unsupervised Learning has no supervisor or agent present to help it go from A to B.
Unsupervised Learning primarily relies on learning and processing the data through pattern recognition between data points. The lack of guidance forces the model to interpret based on unlabeled data.
For example, suppose somebody was looking for hotel suggestions. In that case, a Reinforcement Learning algorithm will dive through the user’s feedback, past experiences, ratings, and more to collate a potential list of hotels the user may prefer or be interested in. However, Unsupervised Learning will look at the past hotel experiences of the user and will suggest similar ones, as the other variables, such as rating and feedback, are unknown.
There are a variety of uses for all three types of Machine Learning. We are still evolving, adapting, and finding new ways to improve the current usage of Machine Learning. Below are the differences between each of these three types of Machine Learning.
Summary of differences of Three Types of Machine Learning
| Characteristics | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Definition | Supervised learning is when the algorithm learns on a labeled dataset and analyses the training data. These labeled data sets have inputs and expected outputs. | Unsupervised learning is when the algorithm learns on unlabeled data, inferring more about hidden structures to produce accurate and reliable outputs. | Reinforcement learning is the training of machine learning models to make a sequence of decisions. It concerns how intelligent agents are to take action in an environment to maximize cumulative reward. |
| Type of data | Labeled | Unlabeled | No predefined data |
| Type of Problem | Classification and Regression | Clustering and Dimensionality Reduction | Reward signal |
| Goal | To predict correct labels for newly inputted data | To find hidden and interesting patterns through similarities and differences between data points | finding an effective model that can maximize the benefits of the reward signal through the trial-and-error method |
| Supervision | Yes | No | No |
| Output | Mapping | Classes | Action |
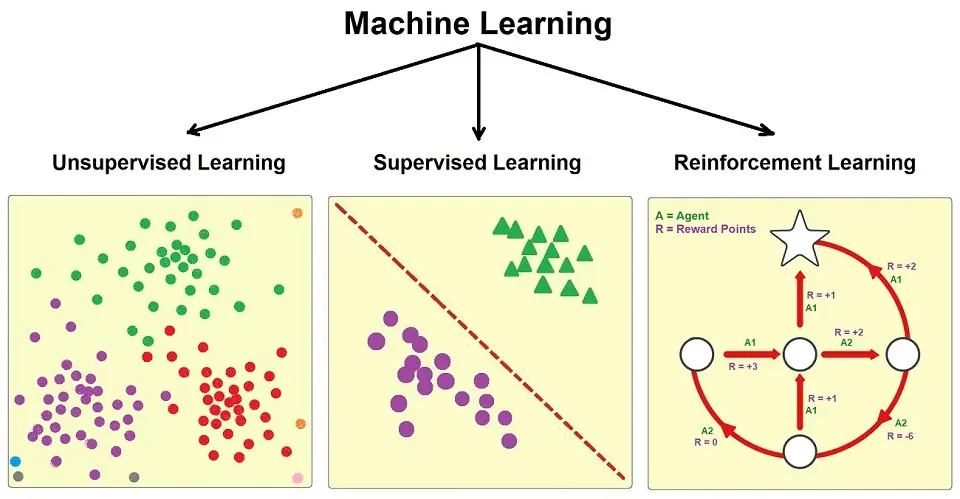
Below is a visual representation of each of the types of Machine Learning:
Applications of Different Types of Machine Learning
- Supervised Learning: It is arguably the most widely used and well-studied type of machine learning. Its popularity arises from its straightforward methodology and applicability to various problems, such as classification and regression, where labeled data is available. Applications range from email spam detection to image recognition and are prevalent across various industries, including finance, healthcare, and e-commerce.
- Unsupervised Learning: It also finds robust usage, especially when labeled data is scarce or unavailable. It’s prominently used for clustering and association problems, such as customer segmentation in marketing, anomaly detection in cybersecurity, or exploring unknown data structures in scientific research.
- Reinforcement Learning: While RL has gained notable attention and achieved successes (e.g., game playing like AlphaGo and robotic control), its application is somewhat specialized due to its unique learning setup and the complexity of designing a rewarding scheme. However, it’s growing notably in areas such as robotics, gaming, autonomous vehicles, and certain aspects of finance, where decision-making over sequential steps is crucial.
In the broad spectrum, supervised learning might be recognized as the most universally applicable and, therefore, possibly the most widely used due to its straightforward applicability to common problems requiring prediction and classification.
However, each type of machine learning has its niche, and the specific problem, available data, and desired outcomes typically determine the “best” approach.
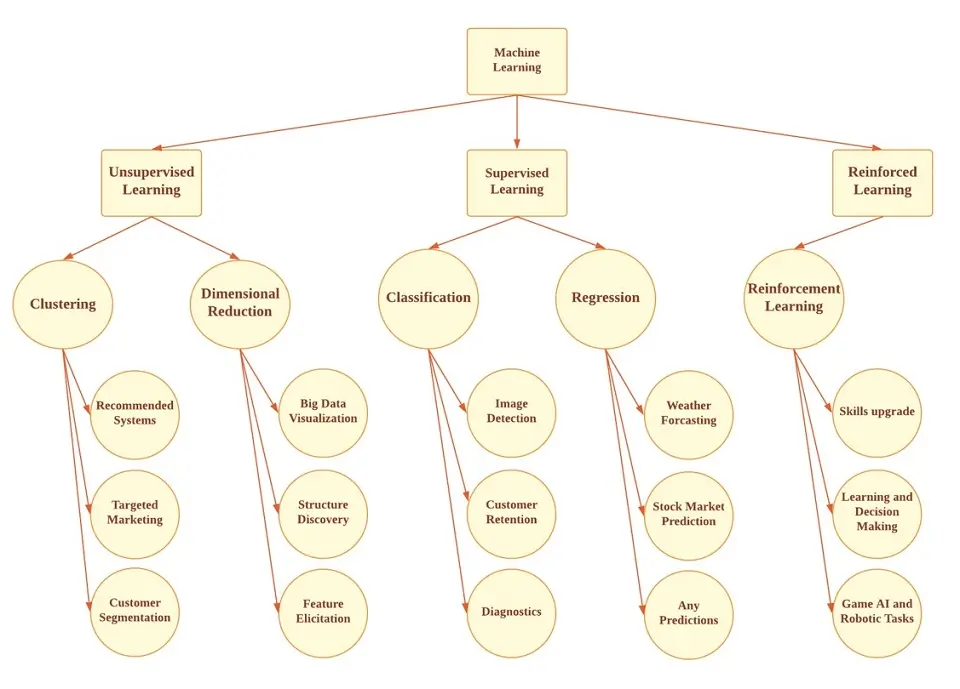
The following diagram shows some examples of the applications of the above-explained three types of machine learning, i.e., unsupervised, supervised, and reinforced machine learning.

Nisha Arya is a Data Scientist and Technical writer from London.
Having worked in the world of Data Science, she is particularly interested in providing Data Science career advice or tutorials and theory-based knowledge around Data Science. She is a keen learner seeking to broaden her tech knowledge and writing skills while helping guide others.