NoSQL Database Interview Questions for Freshers
Preparing for a job interview in the NoSQL database domain involves understanding a range of concepts from the basics of NoSQL databases to more complex querying and database design.
Here’s a mix of 17 fundamental and intermediate questions that are suitable for freshers applying for positions involving NoSQL databases. These questions cover a broad spectrum of topics relevant to NoSQL technologies:
Questions and Answers about NoSQL Databases for Freshers
Q1. What is NoSQL?
NoSQL is a category of database management systems that differs from traditional relational database management systems (RDBMS) in several ways. These databases are designed to handle large volumes of data and support scalable, high-performance applications.
Unlike RDBMS, which use a structured query language (SQL) for data manipulation and follow a fixed schema, NoSQL databases are schema-less and support a variety of data models, including key-value, document, column-family, and graph databases.
NoSQL databases are particularly effective for applications that require real-time analytics, large-scale data storage, and managing data that does not fit neatly into a tabular structure. NoSQL databases are chosen for their flexibility, scalability, and performance benefits when dealing with big data and real-time web applications.
It would also be better to check out the NoSQL interview questions for experienced candidates, even if you are a fresher in the field.
Q2. Why use NoSQL databases?
NoSQL databases are used for their scalability, flexibility, and performance with large volumes of unstructured or semi-structured data. They excel in situations where traditional relational databases may struggle, such as handling rapid growth or databases that are distributed across multiple locations.
NoSQL databases allow for quicker development due to their schema-less nature, making them ideal for agile development environments where requirements can change rapidly. They are particularly well-suited for applications that require real-time analytics, content management, and handling big data, offering efficient storage and access patterns that can scale horizontally to accommodate growth.
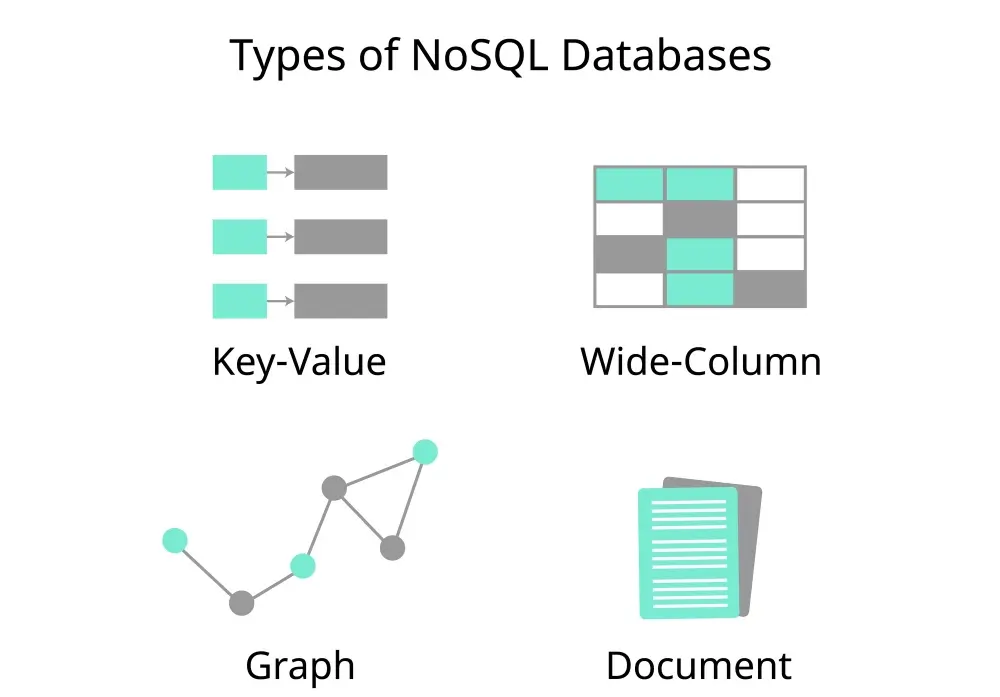
Q3. What are the main types of NoSQL databases?
The main types of NoSQL databases are:
- Key-Value Stores: These are the simplest form of NoSQL databases, storing data as a collection of key-value pairs. They are highly efficient for lookups and are used in scenarios requiring fast data retrieval.
- Document Databases: These databases store data in documents (similar to JSON, BSON, etc.) and are ideal for storing, retrieving, and managing semi-structured data. They allow complex data structures to be stored as documents.
- Column-Family Stores (Wide column): These databases store data in columns rather than rows, making them efficient for reading and writing large volumes of data. They are suitable for analytical applications that require fast data aggregation and querying.
- Graph Databases: Designed to store and navigate relationships, graph databases are ideal for interconnected data. They excel in scenarios where relationships and connections between data points are key to the application.
Q4. Explain CAP Theorem.
The CAP Theorem states that a distributed database system can only simultaneously provide two out of the following three guarantees:
- Consistency: Every “read” receives the most recent “write” or an error.
- Availability: Every request receives a response without guarantee of it containing the most recent write.
- Partition Tolerance: The system continues to operate despite a number of message losses or failures of part of the system (partitions).
In essence, the theorem outlines the trade-offs involved in designing and using distributed systems.
This indicates that while you can optimize for two of these attributes, you cannot simultaneously ensure all three. For instance, a system might choose to prioritize consistency and partition tolerance at the expense of availability, or any other combination depending on the application’s specific needs and requirements.
Q5. What is Brewer’s Theorem?
Brewer’s Theorem is nothing but another name for the CAP theorem.
Q6. What is eventual consistency in NoSQL?
“Eventual consistency” is a consistency model used in many NoSQL databases where it is guaranteed that if no new updates are made to a given data item, eventually all accesses to that item will return the same value. It means that the system allows for temporary inconsistencies during which different nodes might have different versions of the same data.
However, over time, all replicas of the data will converge to the same state. This model allows for high availability and partition tolerance by sacrificing strict consistency. It is particularly useful in distributed systems where immediate consistency of all data across all nodes is not feasible or necessary, providing a balance between performance and data accuracy.
Q7. How does sharding work in NoSQL databases?
Sharding in NoSQL databases is a method of distributing data across multiple servers or nodes to enhance performance, scalability, and manageability.
It involves breaking down a database into smaller, more manageable pieces called shards, each of which can be hosted on a different server or physical location. Each shard contains a subset of the database’s data, allowing operations to be performed more quickly and efficiently because they can be processed in parallel across multiple shards.
Sharding strategies can be based on different criteria, such as the value of a specific key (range-based sharding) or a hash of a key (hash-based sharding), to evenly distribute data and workload across shards. This helps in managing large datasets and high throughput operations by reducing the load on any single server and increasing the overall capacity of the database system.
Proper sharding can lead to significant improvements in application responsiveness and scalability.
Q8. What is a document-oriented database?
A document-oriented database is a type of NoSQL database designed to store, retrieve, and manage semi-structured data in the form of documents.
Unlike relational databases that store data in tables with fixed schemas, document databases use a more flexible model where each document can contain different data structures. Documents are typically stored in formats like JSON, BSON, or XML, allowing for nested data and arrays within the documents.
This flexibility makes document-oriented databases ideal for applications requiring agile development and the ability to store complex data types without a predefined schema.
They are well-suited for content management systems, e-commerce applications, and any scenario where the data model may evolve over time. Document databases provide a high level of scalability and performance for querying and indexing data, making them a popular choice for web, mobile, and IoT applications.
Q9. Explain the concept of a key-value store.
A key-value store is a type of NoSQL database that stores data as a collection of key-value pairs, where a unique key is associated with a value. It’s one of the simplest database types, providing a highly efficient method for data retrieval by key. In a key-value store, the value is a blob that is entirely opaque to the database, meaning the database does not interpret the value itself.
This model allows for fast and scalable data access, making key-value stores ideal for applications that require rapid, high-volume data retrieval, such as caching, session storage, and real-time recommendation systems.
Due to their simplicity and efficiency, key-value stores are often used in scenarios where the data structure is simple or where the application does not require complex queries or relationships between data points.
Q10. What are secondary indexes in NoSQL databases?
Secondary indexes in NoSQL databases are structures that allow you to query data based on non-primary key attributes.
While the primary key index allows for efficient querying by the primary key, secondary indexes provide a way to access data through other attributes or fields within your data model. This means you can perform queries based on values that are not the primary key, enhancing the database’s flexibility and query capabilities.
Implementing secondary indexes can significantly improve the performance of read operations for specific query patterns, making it easier to retrieve data based on criteria other than the primary key.
However, it’s important to use them judiciously, as they can introduce additional overhead for write operations, since each write may require updating one or more secondary indexes. Secondary indexes are particularly useful in scenarios where you need to support diverse query requirements and access patterns in your application.
Q11. How do transactions work in NoSQL databases?
Transactions in NoSQL databases vary significantly across different types of databases and their implementations.
Traditionally, NoSQL databases were designed to optimize for scalability, performance, and flexibility, often at the expense of strict transactional guarantees provided by ACID (Atomicity, Consistency, Isolation, Durability) properties common in relational databases.
However, many NoSQL databases now support transactions to some extent, allowing for atomic operations across multiple documents, keys, or entries. These transactions can range from simple, single-document updates to more complex, multi-document and cross-collection operations.
- Atomicity: Ensures that all operations within a transaction are completed successfully or none at all.
- Consistency: Guarantees that a transaction brings the database from one valid state to another, maintaining database invariants.
- Isolation: Controls how and when the changes made by one transaction are visible to other transactions.
- Durability: Ensures that once a transaction has been committed, it will remain so, even in the event of a system failure.
Q12. What is data modeling in the context of NoSQL?
Data modeling in the context of NoSQL involves designing the structure and organization of data in a way that optimizes for the strengths and use cases of NoSQL databases, such as scalability, performance, and flexibility.
Unlike traditional relational data modeling, which relies on a fixed schema and relationships defined by foreign keys, NoSQL data modeling focuses on how data is accessed and used by the application.
This process includes deciding on the appropriate NoSQL database type (e.g., key-value, document, column-family, graph) based on the application’s requirements, structuring data to support efficient queries, and considering how the data will scale across distributed systems.
It often involves denormalization, or the duplication of data, to reduce the need for joins and to improve read performance. Additionally, data modeling for NoSQL databases takes into account the trade-offs between consistency, availability, and partition tolerance (as per the CAP theorem), ensuring that the data architecture supports the application’s specific needs for performance and reliability.
Q13. Can NoSQL databases be used for relational data?
Yes, NoSQL databases can be used to store and manage relational data, but with some considerations.
While NoSQL databases are not inherently designed for relational data management, they can accommodate relationships through different modeling techniques such as embedding documents (in document databases), using adjacency lists (in key-value or column-family stores), or directly leveraging graph databases for inherently relational data.
However, when using NoSQL for relational data, it’s important to carefully design the data model to ensure efficient access patterns and query performance, as NoSQL databases do not support joins and other relational operations in the same way SQL databases do.
This often involves denormalizing data or implementing application-level joins, which can complicate the application logic but can offer scalability and performance benefits for certain types of queries and workloads. The choice to use NoSQL for relational data should be driven by specific requirements such as scalability, flexibility, and the nature of the data and queries.
Q14. What is a graph database, and give an example of its use case?
A graph database is a type of NoSQL database designed to store, manage, and query complex networks of data as graphs.
It represents data as nodes (entities), edges (relationships), and properties (information about entities and relationships). Graph databases excel at managing interconnected data and are optimized for traversing relationships in real-time, making them ideal for use cases where relationships between data points are key to the application.
One common use case for graph databases is social networking applications. In these applications, users are represented as nodes, and the relationships between them (such as friendships, likes, or follows) are represented as edges.
Graph databases allow for efficient querying and analysis of the network, enabling features like finding the shortest path between two users, recommending new friends based on mutual connections, or analyzing social networks to identify influencers and communities.
Other use cases include recommendation engines, fraud detection, network and IT operations, and more, where the ability to quickly navigate and analyze complex relationships can provide significant advantages.
Q15. How do you ensure data integrity in NoSQL databases?
Ensuring data integrity in NoSQL databases involves a combination of database features, application logic, and best practices tailored to the specific NoSQL database type and use case. Here are key strategies:
- Schema Design: Thoughtful data modeling and schema design can help maintain data integrity by structuring data in a way that reduces redundancy and inconsistency. For document databases, embedding related data in a single document can ensure atomic updates.
- Transactions: Utilize transactions where supported. Some NoSQL databases offer ACID-compliant transactions for operations involving multiple documents or keys, ensuring atomicity, consistency, isolation, and durability.
- Validation: Implement validation at the application level. Since NoSQL databases are schema-less or have flexible schemas, it’s important to validate data before writing it to the database, ensuring it meets the expected format and constraints.
- Use of Constraints: Where possible, apply constraints such as unique constraints on key attributes to prevent duplicate data entries.
- Version Control: Implement version control mechanisms for documents or rows to manage concurrent updates, ensuring that changes are applied on the correct version of data.
- Consistency Levels: Leverage configurable consistency levels for read and write operations (if available) to balance between performance and data accuracy based on the application’s requirements.
- Regular Audits and Backups: Conduct regular data audits to check for integrity issues and maintain regular backups to ensure data can be restored in case of corruption.
Q16. What challenges might you encounter when migrating from SQL to NoSQL?
When migrating from SQL to NoSQL, you might encounter several challenges due to fundamental differences in data modeling, query language, and transaction management. Key challenges include:
- Data Modeling: NoSQL databases often require a different approach to data modeling, focusing on denormalization and document or key-value structures. Adapting relational data models to fit NoSQL paradigms can be complex.
- Query Language Differences: SQL databases use a standardized query language (SQL), while NoSQL databases may use various query languages or APIs. Developers must learn new ways to interact with data, impacting development time and complexity.
- Transactions: SQL databases offer ACID transactions for consistency across multiple operations. While some NoSQL databases support transactions, they might be limited or behave differently, requiring adjustments in application logic.
- Consistency: Ensuring data consistency can be more challenging in NoSQL, especially in distributed systems where eventual consistency is common. Applications may need to be designed to handle eventual consistency.
- Indexing and Searches: Implementing efficient searches and indexing strategies in NoSQL can be different and sometimes more complex than in SQL databases, particularly for complex queries.
- Tooling and Support: The ecosystem around NoSQL databases, including management tools, integrations, and community support, may differ, requiring teams to adapt or develop new tools.
- Performance Considerations: While NoSQL can offer scalability and performance benefits, these can vary greatly depending on the data model and access patterns. Performance tuning requires understanding the specific NoSQL database’s behavior.
Q17. Can you name some of the main NoSQL databases and briefly describe their use cases?
Here are a few key NoSQL databases and their typical use cases:
- MongoDB: A document-oriented database, ideal for applications requiring complex data structures to be stored, queried, and indexed efficiently. Commonly used in content management systems and mobile apps.
- Cassandra: A wide-column store that offers high scalability and availability, making it suitable for applications that need to handle large volumes of data across multiple data centers, such as IoT and time-series data.
- Redis: An in-memory key-value store, known for its speed and efficiency in caching, session management, and real-time analytics applications.
- Neo4j: A graph database designed for applications that heavily rely on understanding and navigating relationships between data points, such as social networks or recommendation engines.
- Couchbase: A document database that combines the flexibility of document models with the power of in-memory performance, suitable for interactive applications.
- DynamoDB: A managed NoSQL database service provided by AWS, designed for applications that need consistent, single-digit millisecond latency at any scale, commonly used in gaming, mobile apps, and IoT.
Other Tech Interview Questions Lists
- Java Interview Questions
- Python Interview Questions
- JavaScript Interview Questions
- iOS Interview Questions
- Android Interview Questions
- NoSQL Interview Questions for Experienced
- Data Engineer Interview Questions