Adversaries in Machine Learning
Adversaries in Machine Learning? When we talk about new technological developments, sometimes we forget that there is another side for whom it’s an opportunity to find new ways to scam.
We are using Machine Learning (ML) models more and more each day. They have become a part of our lives without even realizing it most of the time. It is used in email spam filters, speech/facial recognition, self-driving cars, etc.
There are a lot of blogs, articles, and tutorials around Machine Learning. However, few people speak on what keeps Machine Learning models safe from cyber-attacks. Let’s discuss Adversaries in Machine Learning.
What are Adversaries in ML?
As we become more dependent on machine learning models to improve our lifestyle, it also raises the question of adversaries, cyber security, and the vulnerabilities of defeating these models.
The Cyber security department refers to this as “adversarial machine learning.” Adversarial machine learning attempts to deceive and trick models by creating deceptive inputs, which confuses the model, resulting in a model malfunction.
I will be using the terminology Adversary a lot in this article. An adversary is one’s opponent in a contest, conflict, or dispute.
An example of Adversarial Machine Learning, as mentioned above, is machine learning models that are used in filtering spam emails.
If an adversary attacks this model, they will alter the spam filter properties, such as misspelling a ‘bad’ word or inserting a ‘good’ word. This could lead to your inbox being overfilled with spam emails due to the insertion of a word/phrase such as ‘make more money’ being classified as ‘good.’

An adversary aims to input data that compromises the output and exploits the vulnerabilities of the machine learning model. However, these inputs are not easy to identify through the human eye, but a way to indicate them is when the model fails.
In Artificial Intelligence, vulnerabilities can exist in the text, audio files, images, and other data used in the training phase when building machine learning models. Digital attacks are much easier to perform; for example, manipulating only one pixel in image recognition is enough to cause misclassification.
How do Adversaries Attack Machine Learning models?
There are two ways adversaries can attack Machine Learning models: a white-box attack or a black-box attack.
A White-Box attack is when the Adversary has full access to the target model, including the architecture and parameters, allowing them to create adversarial samples and try to manipulate the target model. The Adversary typically has full access due to being a developer who is testing the model,
A Black-Box attack is when the Adversary has no access to the target model and can only examine the model’s outputs. Instead, the adversary generates adversarial samples by using query access.
Types of Adversarial Attacks on ML Models
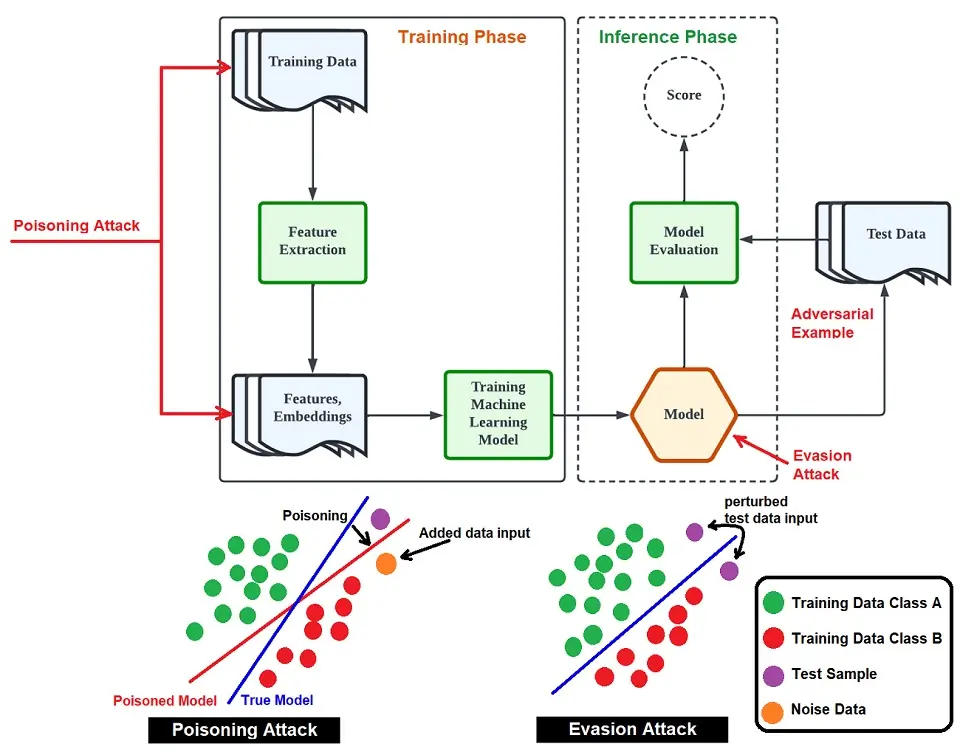
1. Poisoning attack
During the training phase, adversaries can create attacks called ‘poisoning or ‘contaminating.’ The Adversary would need full access to the training data, making this a white-box attack.
For example, an adversary will input incorrectly labeled data to a classifier, which they will label as harmless. However, it has a negative impact. This leads to misclassification, which produces incorrect outputs and highly affects the decision-making process.
Another form of poisoning is decreasing the accuracy of the model. The Adversary can achieve this by slowly inputting poisoned data into the model, known as model skewing.
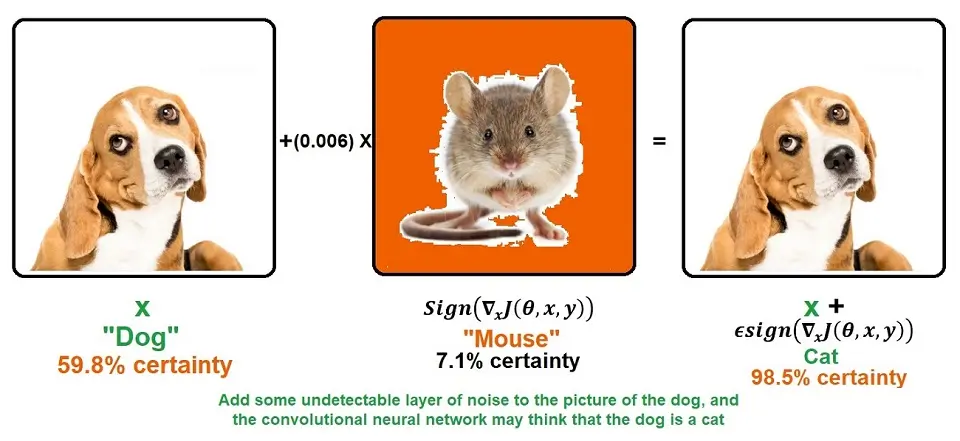
Note: By adding some undetectable layer of noise to the dog’s picture, the convolutional neural network may think the dog is a cat.
2. Evasion attacks
Evasion attacks typically occur once a machine learning model has been trained, allowing adversaries to input new data. These attacks are also known as white-box attacks.
An evasion attack is much harder to achieve than a poisoning attack. In a poisoning attack, the Adversary has to know about the machine learning model, its limitations, parameters, etc.
However, with an evasion attack, the Adversary does not know what causes the machine learning model to break. Therefore, the Adversary will have to develop attacks through trial and error, helping them understand the model better and how to manipulate it.
If we use the spam email example, an adversary may experiment with emails the model has been trained to screen and flag as ‘spam.’ For example, if the model has been trained to filter out emails containing words such as “make more money” or “get paid,”. The Adversary will create new emails with words linked to “make more money”, allowing it to pass through the algorithm. This move can prevent the email from being classified as spam.
Other evasion attacks are more harmful, such as using Natural Language Processing (NLP) to extract personal information such as identification numbers and banking details for the Adversary’s monetary gain.
Below is an image that distinguishes the difference between poisoning and evasion attacks.
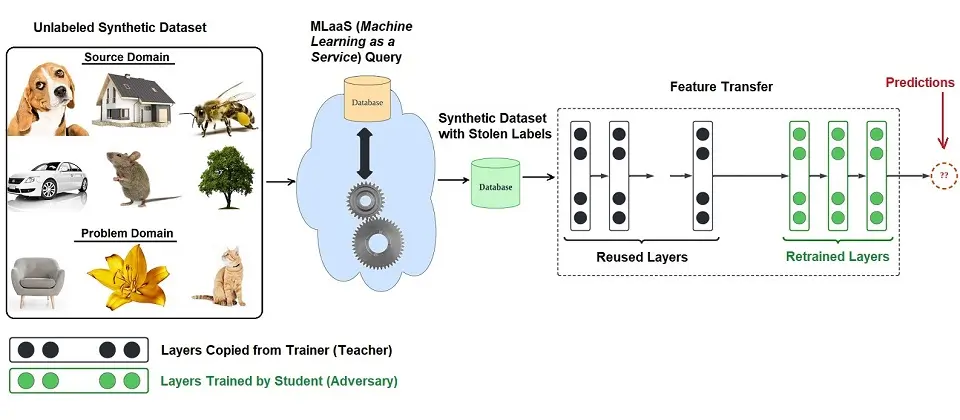
3. Model Extraction
We’ve spoken about white-box attacks. What about black-box attacks? This is where Model extraction comes into the picture.
Black-box attackers do not have access to the model. Therefore, they aim to try and rebuild the model from scratch or specifically extract the output data. Model extraction typically occurs with highly confidential models and has some form of monetary gain if the model is attacked, for example, the stock market prediction model.
The model extraction attack process typically entails the data owner training an original model and delivering predictions on the trained model to the Adversary. This way, the Adversary can rebuild their own model through imitation. By its end, the Adversary will have recreated the model through continuous tuning.
Adversaries charge others, such as the data owners or other developers, who can access the model and its parameters on a pay-per-query basis for the model’s outputs.
How to Avoid Adversaries from Attacking Your ML Models?
1. Adversarial Training
Attack before getting attacked! This is where you aim to improve your machine learning model’s overall efficiency and defense system. Therefore, you generate attacks on it.
Machine Learning models are built to learn to produce better outputs. Generating adversarial examples and inputting them into the model will allow it to learn the attack and identify future attacks. Look at it like the machine learning model builds its immune system.
However, it is difficult to fully understand an adversary’s next move, especially if you don’t know them or know their intention.
2. Changing your model frequently
Altering your algorithm frequently, the parameters, the training data, and others is a good approach to creating challenges and hurdles for the Adversary.
A good way to understand what to change is by breaking your model. This way, you can understand the weaknesses of your model and how to improve it. In addition, this will make it harder for adversaries to learn, imitate, and duplicate the model.
3. Defensive distillation
Defensive distillation is a process used to smooth out the model’s decision phase, making it difficult for an adversary to identify any issues or problems that can help them carry out their attack. It adds flexibility to the machine learning model classification process, making the model less susceptible to exploitation.
During distillation training, one model is trained to predict the output probabilities of another model trained earlier. The first model is trained with “hard” labels to achieve maximum accuracy, whereas the second model learns the uncertainty of the first model, and this is used to train in the second model, acting as an additional filter.
Conclusion:
If you adopt machine learning and artificial intelligence into your business, work, and more. You will need to consider the risk you face with adversaries highly. Implementing the right protocols will help you reduce data breaches, theft, monetary loss, and more.

Nisha Arya is a Data Scientist and Technical writer from London.
Having worked in the world of Data Science, she is particularly interested in providing Data Science career advice or tutorials and theory-based knowledge around Data Science. She is a keen learner seeking to broaden her tech knowledge and writing skills while helping guide others.